本日の帷子川情報です
December 23, 2013
この記事は MySQL Casual Advent Calendar 2013 の 23 日目です。
業務でMySQLを使っていない場合、なかなか深い知見というものを得られないとは思います。
今回は常日頃自分が気になっていることをメモしておき、
データとして利用する一例を記します。
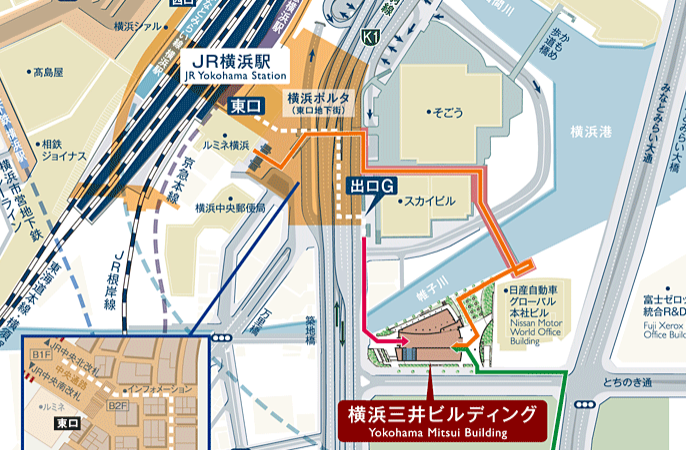
横浜駅から横浜三井ビルディングへ向かうと、途中で築地橋という橋を渡ります。
その築地橋の下には帷子川が流れ、目の前の相模湾へと続いているのですが
毎日見てみると、丁度築地橋の付近で陸地から海へと流れるはずの川の流れが
たまに逆流していることがあるのに気付きました。
これは面白いなと思い、通る度にTwitterへメモを残すようにしていました。
今回はそのデータを利用し、何か面白い情報が得られないか確認してみようと思います。
本来であれば、天候、風、気温などの複合的情報があって
精度の高いデータとして利用できるのですが、
川を見てメモをする以上の作業を増やしたくなかったので
今回は行いませんでした。
まず、tweets.zipをMySQLに入れる作業ですが、以前メモをした内容の通りに行います。
メモ記載当時だとtweets.csvのフォーマットが
"tweet_id",
"in_reply_to_status_id",
"in_reply_to_user_id",
"retweeted_status_id",
"retweeted_status_user_id",
"timestamp",
"source",
"text",
"expanded_urls"
という並びだったのですが、現在は
"tweet_id",
"in_reply_to_status_id",
"in_reply_to_user_id",
"timestamp",
"source",
"text",
"retweeted_status_id",
"retweeted_status_user_id",
"retweeted_status_timestamp",
"expanded_urls"
という並びに変更になっています(2013/12/23現在)。
新しくretweeted_status_user_id,retweeted_status_timestampという
2つのステータスが取得できりるようになっています。
テーブルも新しい仕様に変更します。
CREATE TABLE tweets (
`id` INT UNSIGNED NOT NULL AUTO_INCREMENT,
`tweet_id` BIGINT UNSIGNED,
`in_reply_to_status_id` BIGINT UNSIGNED,
`in_reply_to_user_id` BIGINT UNSIGNED,
`timestamp` TIMESTAMP DEFAULT 0,
`source` VARCHAR(255),
`text` VARCHAR(140),
`retweeted_status_id` BIGINT UNSIGNED,
`retweeted_status_user_id` BIGINT UNSIGNED,
`retweeted_status_timestamp` BIGINT UNSIGNED,
`expanded_urls` VARCHAR(255),
PRIMARY KEY (id) )
ENGINE = InnoDB DEFAULT CHARACTER SET utf8;
データをインサートします。
mysql> LOAD DATA INFILE '/Users/kenjiskywalker/Downloads/tweets/tweets.csv' \
INTO TABLE tweets FIELDS TERMINATED BY "," ENCLOSED BY '"' LINES TERMINATED BY "\n" IGNORE 1 LINES \
(tweet_id, in_reply_to_status_id, in_reply_to_user_id, timestamp, source, text, \
retweeted_status_id, retweeted_status_user_id, retweeted_status_timestamp, expanded_urls);
うまくデータがインサートされたか確認します。
mysql> SELECT COUNT(text) FROM tweets WHERE text LIKE "%本日の帷子川情報です%";
+-------------+
| COUNT(text) |
+-------------+
| 119 |
+-------------+
1 row in set (0.03 sec)
mysql>
この時点で自分が想像していた1/3ぐらいのデータ量で、
別の内容に変更しようと考えましたが諦めずに続けたいと思います。
mysql> SELECT timestamp,text FROM tweets WHERE text LIKE "%本日の帷子川情報です%" LIMIT 3;
+---------------------+------------------------------------------------------------------------------+
| timestamp | text |
+---------------------+------------------------------------------------------------------------------+
| 2013-11-14 01:04:00 | 流入あり #本日の帷子川情報です |
| 2013-11-13 01:30:56 | 流入あり #本日の帷子川情報です http://t.co/c4hCPjgx5B #gifboom |
| 2013-11-12 01:25:46 | 流入あり #本日の帷子川情報です |
+---------------------+------------------------------------------------------------------------------+
3 rows in set (0.00 sec)
mysql>
正確なデータが入っていることが確認できました。
それではまず、流出と流入の割合を調べてみましょう。
mysql> SELECT COUNT(id) FROM tweets WHERE text LIKE "%本日の帷子川情報です%";
+-----------+
| COUNT(id) |
+-----------+
| 119 |
+-----------+
1 row in set (0.03 sec)
mysql> SELECT COUNT(id) FROM tweets WHERE text LIKE "%本日の帷子川情報です%" AND text LIKE "%流出%";
+-----------+
| COUNT(id) |
+-----------+
| 33 |
+-----------+
1 row in set (0.03 sec)
mysql> SELECT COUNT(id) FROM tweets WHERE text LIKE "%本日の帷子川情報です%" AND text LIKE "%流入%";
+-----------+
| COUNT(id) |
+-----------+
| 62 |
+-----------+
1 row in set (0.04 sec)
特に意識していなかったのですが、いくら海が近いとはいえ
陸から海へと流れ出る(流出)より海から川へと逆流していく(流入)割合の方が倍近くありました。
検証データの怪しさが見えますね。
これだけでは面白くないので月の満ち欠けを含めて確認してみましょう。
今回個人的にやりたかったのはこれです。
hamweather.comのAPIから月の遷移のデータをとってきます。
CREATE TABLE moon (
`id` INT UNSIGNED NOT NULL AUTO_INCREMENT,
`timestamp` TIMESTAMP DEFAULT 0,
`moon_state` VARCHAR(140),
PRIMARY KEY (id) )
ENGINE = InnoDB DEFAULT CHARACTER SET utf8;
このようにmoonというテーブルを作成し、moon_stateに取得した月の状態を
timestampには%Y-%m-%dのフォーマットのtimestampがはいります。
それでは関連性を調べてみましょう。
mysql> SELECT DATE_FORMAT(timestamp, "%Y-%m-%d") AS timestamp, moon_state FROM moon WHERE timestamp IN \
(SELECT DATE_FORMAT(timestamp, "%Y-%m-%d") FROM tweets WHERE text LIKE "%本日の帷子川情報です%" AND text LIKE "%流出%");
+------------+---------------+
| timestamp | moon_state |
+------------+---------------+
| 2013-09-05 | new moon |
| 2013-04-26 | full moon |
| 2013-04-18 | first quarter |
+------------+---------------+
3 rows in set (0.03 sec)
mysql>
mysql> SELECT DATE_FORMAT(timestamp, "%Y-%m-%d") AS timestamp, moon_state FROM moon WHERE timestamp IN \
(SELECT DATE_FORMAT(timestamp, "%Y-%m-%d") FROM tweets WHERE text LIKE "%本日の帷子川情報 です%" AND text LIKE "%流入%");tamp
+------------+---------------+
| timestamp | moon_state |
+------------+---------------+
| 2013-09-27 | last quarter |
| 2013-09-19 | full moon |
| 2013-08-21 | full moon |
| 2013-08-14 | first quarter |
| 2013-07-30 | last quarter |
| 2013-07-08 | new moon |
| 2013-06-17 | first quarter |
+------------+---------------+
7 rows in set (0.03 sec)
mysql>
出、出〜!サブクエリLIKE連奴〜!
SQLを発行するときはちゃんとEXPLAINして不要なクエリを発行しないようにしましょうね。
moon_stateがfullmoonのものを抽出してみます。
mysql> SELECT DATE_FORMAT(timestamp, "%Y-%m-%d") AS timestamp, moon_state FROM moon WHERE timestamp IN \
(SELECT DATE_FORMAT(timestamp, "%Y-%m-%d") FROM tweets WHERE text LIKE "%本日の帷子川情報です%" AND text LIKE "%流出%") AND moon_state = "full moon";
+------------+------------+
| timestamp | moon_state |
+------------+------------+
| 2013-04-26 | full moon |
+------------+------------+
1 row in set (0.05 sec)
mysql>
mysql> SELECT DATE_FORMAT(timestamp, "%Y-%m-%d") AS timestamp, moon_state FROM moon WHERE timestamp IN \
(SELECT DATE_FORMAT(timestamp, "%Y-%m-%d") FROM tweets WHERE text LIKE "%本日の帷子川情報です%" AND text LIKE "%流入%") AND moon_state = "full moon";
+------------+------------+
| timestamp | moon_state |
+------------+------------+
| 2013-09-19 | full moon |
| 2013-08-21 | full moon |
+------------+------------+
2 rows in set (0.04 sec)
mysql>
流出:流入 = 2:1 なので、傾向は出ていないように見えます。
参照データ量が少ないので、なんともですが
もう少し面白い結果が出てきてくれたら楽しかったですね。
月の満ち欠け、何も関係ねーじゃねーか
— kenjiskywalker (@kenjiskywalker) December 21, 2013はい。ということでMySQLを利用すれば、_好きなあの子のバスの乗車時刻_や
_あの人いつもあの服着てる気がする_。など、
日頃から気になることをメモしておくことで、
実際に検証することが可能になるのでおすすめです。
明日(12⁄24)はからあげエンジニアでおなじみの@sasata299さんです。